���ѣ�win11�ƹ�Ӳ�����ư�װ һ����װWin10ϵͳ ��ɾ���u�������� �����������win7ϵͳ
�༭��jiayuan 2017-05-24 16:54:09 ��Դ�ڣ�IT֮��
�������������Ͽ�����������ܶ��ְҵΧ����ֲ�ȡ����60��ʤ���°�AlphaGo����ǰ����������������ķ�֮һ�ӵ�������սʤ�����������һ���й����ֿ½ࡣȻ���ⲻ���������˹����ܵ�ǿ��Ҳ�����Ƕ���һ���������µ���֪����ô���ǿ����˹����ܣ�������Χ����Ŀ�л��л�ʤ��ϣ����
������˵�����ۣ��ٿ�������
����1.��Χ�������Ŀ��AlphaGoĿǰ�����������ǰ�棬����û����ȫ����Χ�������˶�����ֻ��ͨ�����ѧϰ�ҵ���һ����������ʶ���ŵĽ⣬���������Ž⡣���Ž����ҵ��������þ����������е���Դ����רҵ�ĽǶ����������������ѧϰȥ�ƽ���һ��ǿ��ѧϰ�еļ�ֵ�жϺ�����Ȼ���ٸ����ؿ�����������ϵķ�������Ȼ�˹����ܺ���������ҵ����Ž⣬����˵��һ���Ѿ���ȫ����ʧ�ܻ��硣
����2.����Ҳ���ڽ����ģ�����Ҳ��Ҫ�����������Ŀ��٣�С������ѧϰ���������AlphaGo�������ڵ�ѧϰ�����������������������˻�ʤ����С������Զ������δ��5-10�꣩�˻��л��ᣬ��Ϊ��Ҳ�к�ǿ��ѧϰ���������Դ�������AlphaGo�Ķ��ĵ�����п���ѧϰ���������ٸ�AlphaGo1�ڸ����ף�������һ���GPU��������ǻ������е�ѧϰ��ϵ�����������ٶ�Ҳ�ս��Ż�����Ϊ���������ͼ�����Դ�����2x10171��������ռ���˵ֻ�Dz�һ�ڡ����Ƕ����Ե��˽Զ�����Χ�����ʶ�������滹�кܴ��δ֪����
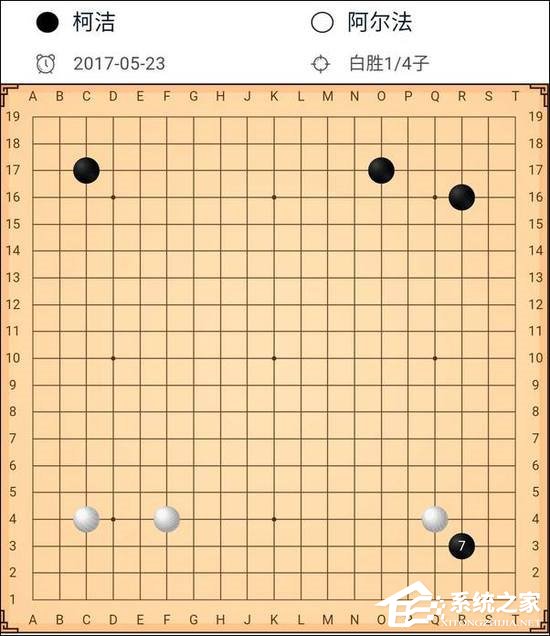
�½���³�����“��·3”����Ȼ�߸����ٶ�ʮ������Χ������
��������ʵ���ϣ��½������²�������Ѫ���������ڸ���ְҵ�������Ѷ��������������������ְҵ����“����”��������й�“Χ��”ְҵ�����У�����“����”������������������Ҳ�Ѳ�������Ҷ������Լ������Ⳣ���˹������³������������½��ְҵ���ֵ�“ι�в���”��Ҳ���й��Լ���Χ���˹�����“����”���ٳɳ�����Ҫ���ء���

��ʵ�ϣ���һ�п½����ڶ�����ĶԾ��г��Զ��

�־Ͷ�������ѧϵ��“ѧ��������”���Ҳ���Զ�������
����3.Ŀǰ����ְҵ���ָ�AlphaGo�IJ��Ҳ����һ����Ŀ��ˮƽ��û�д���������ô����ʵ�����Ŀ�IJ�ࣨ���й���7Ŀ�룩����ְҵ���ֿ������Ѿ��Ƿdz���IJ���ˡ��ܶ�ְҵ���֣�������ӽκ����Լ������Է�7-8Ŀ���ͻ�����Ͷ�������ˡ��ܶ�ͨ������������ʤ���ı�������Ӯ��������1-2Ŀ֮�䣨����½�����AlphaGo��Ŀ��������ᱻ����רҵ����Ц�����Լ������ô���֪�����������̫���ˡ�
����Ҫ�������ۡ�ȷ�Ŀ���������⼱��Ҫ��ǿ���˹�����רҵ֪ʶ��Ҳ��Ҫһ����Χ�幦�ס������Ⱦ���������֪��һЩ������
��������һ��AlphaGo���������ඥ������4���ӣ�AlphaGo2.0��������һ���汾4-5���ӡ�
����Ҫ���������⣬����Ҫ������ռ�һ��Χ��֪ʶ����Χ����“�öԷ�������”��“Ӯ�Է�2����”��������֮����������Χ����˲��ö�˵�����ҽ������ʶ�����ܶ�Թ�Ⱥ��һֱ��Ϊ�����һ���¡��ѹ����ϻ��������ϵĴ������ۡ�
�����öԷ������ӣ���Χ������2����˵��һ�����������Ϸ���2�����ӣ�����ֻ�ܷ�����λ����Ȼ��Է��ſ�ʼ�ߡ����������ڶ���֮���ļ�ֵ����רҵ����������ÿ�����Ӽ�ֵ������10Ŀ���ϣ�������ع����ˣ����������൱���������ó�ȥ�Է�20��Ŀ�ĵ��̡��������������ģ���������ں���ı����У������Ŀռ���Ӯ����20��Ŀ���Ǿ�������ʧ���ˡ�����������Խ�࣬���÷���õļ�ֵ���������������ģ���Ϊ����֮����γ���ϣ���ȡ��������档����˵�����ӣ����ֵ�Ϳ���Զ��ֹ40Ŀ�ˡ�
����Ӯ�Է�2���ӣ���ָ˫�������Ӯ��һ�������һ�����2���ӡ�������ճ�ס�Է�һ��������Ŀ�ķ������㣬��2����ֻ�൱��4Ŀ��AlphaGoӮ�˿½�1/4�ӣ����൱�ڰ�Ŀ���Ӷ��ѡ�
��������“�öԷ�������”��“Ӯ�Է�2����”����ͬ������������Χ��֮����ڣ�����һ�����ҵ����Ž⣬��������û��ϣ���¹����ģ���һ�㶥��רҵ������Ϊ���Ǹ������IJ������2-3��֮�䡣����AlphaGo���Ա�֤�����ܱ�֤�ҵ����Ž⣬������������һ���ľ��롣��ˣ�˵AlphaGo���������ඥ������4���ӣ����ֱ�����췽ҹ̸��
������������AlphaGoҲ���³�һЩ���Բ��õ�����������Ϊ�������ж���ʽռ�ţ���������������Ҫ��
����AlphaGo���������Ծ������ȶԻ�ʤ���ʱȽϴ�ķ�֧���и�����������������������κ�ʱ����ı䣬Ҳ���ܸı䡣����������Լ������˾��³����֡��µò��õ�ʱ������Ϊ���ֵ�жϱ�������һ�����ƣ����������ռ�Ҳ��������ò������Ž⣬��ˣ���ʱ���ƻ��������壬��ʵ��һ���������õ��·���AlphaGo�������ֲ��ȶ�״���������ġ���Ҳ�������ƴ��ϣ�����ڡ���Ȼ����Ҳ�����������㣬��ƣ�͡����������ȣ���Ҳ���ж�ʧ������ֺܳ�����Щ֮ǰ��̫�õ��壬��������ı仯����������Ԥ���еı仯���п��ܻ��ɺ��塣���ԣ��������еĴ�����ֱ��Ӱ�쵽�����Ľ�����������ڴ���ƺ��е���AlphaGo�ˣ�������AlphaGo�³�һ�в��õ��壬��Ҹ�����ǻ����Լ���ˮƽ���Dz�������û��������������ѡ������AlphaGo��“��ıԶ��“��
������������AlphaGo���Բ�����ѧϰ�����µ�������ȡ���飬���������Լ���
����AlphaGo��ϵͳ���ڲ����dz��࣬��Ҫ������������ѵ���������ļ���������������������κ����á�����AlphaGo������������ʱ�����һ�������ݵ������Ż���Ҳ����Ժܶ�����������������ѵ��ʱ��dz������������ںܶ�ʱ���ڴ������������ˮƽ��������ͬһ��ѵ�����ף���������������һ��Ҳ��ѵ��������ˮƽ����ϴ��ϵͳ����ʵAlphaGo��ͨ�����Ҷ��������ɺܶ����ף�Ȼ�����������еģ����������ģ����������ʤ����Ӧ��ϵѵ������ֵ������������ֻ�ǽ�����һ��ǿ��ѧϰ�Ŀ����ѵ�����������IJ������ѣ���Ҫ���������ѧϰ�Ľ������������ģ�����˴�ͳǿ��ѧϰ��Ը��ӻ����Ͷ���״̬���������⣩����ˣ�AlphaGo��û�д��������������Ҳ��ľ����Լ����Ͻ�����������
���������ģ�AlphaGo������ˮ���һ�ֱ�����
�������û�п��ܡ�Ҫ���仹���������ô�ѿ������ԣ���һ���dz��Ѱ�����飬���ܱ�Ӯ�廹Ҫ�ѡ���ģ��ѵ����֮��AlphaGo�ܹ���ʱ�Ķ���ֻ������������Ͷ�����Դ���٣��������Ŀռ䣩���ԸĶ���������̫С������������̫��仯�����������̫�࣬�ͻ��³�һЩ�dz��ͼ������������Ӽ����Ƕ��������Ѱ��ա�
���������壺������ļ�������һ������ǿ�����Բ�Ҫȥ��AlphaGo�ȼ��㣬Ӧ�ðѾ���������⸴�ӵ�ս����
����AlphaGo��������һ�ֻ������������㷨���������Ӿ��������ռ���δ����Ӯ�ļ�ֵ�ж�Ҳ����ѡ���ˣ����㲻�����ĸ��Ӿ��棬��AlphaGo��˵Ҳ�����ѡ��������̫���������Էdz��õļ�����Ƚ��ŵĽ⣬�������ָ���û��ϣ������ˣ��Ѿ���Ū���ӣ��������ֲ���ϣ����ʤ����Ȼ���������Ҳ����˸������ս��
�����ܽ�
������������Ŀǰ��Χ�����ʶ�����⣬�ֽ��������ɻ�����˹����ܡ���ͨ����AlphaGo�IJ��ģ�����Ҳ��������ʶΧ�塣ֻҪ�����˼��������ڲ��Ͻ������˾��п�����δ��5-10����ͨ�����ϵ�ѧϰ���ϵ�ǰ��AlphaGo����Ȼ��AlphaGoҲ������������Ͼ�������Χ��֮��Ҳû�й���Χ��������⡣������е�ѧϰ����û��ȫ��ĸ��£����Ľ������ٶ�Ҳ�������Ż����������Ƕ�Χ�����˸���������˽�֮���ֻ���Ƴ���������˹������㷨��������ʵ����ì�ܣ��ศ��ɣ�����ٽ�������˭��˭Ӯ���������������������֡����������Ҳ��ʼ�����ڻ�����ǰ�棬�����ᱻ����ȡ����






��������
��0��
���۾���Щ�����ô��Ҳ֪����Ķ��ؼ���
���������������Խ������û����˹۵㣬������ϵͳ֮������